-
- #4.1: Recurrent Neural Networks
- #4.2: RNN and LSTM Cells in PyTorch (Lab)
- #4.3: Language Modeling with RNNs
- #4.4: Building a Word-Level Language Model in PyTorch(Lab)
- #4.5: Encoder/Decoder RNN for Language Translation (Seq2Seq)
- #4.6: Building an Encoder/Decoder RNN in PyTorch (Lab)
- #4.7: Attention Mechanism for Seq2Seq RNNs
- #4.8: Adding Attention to the Language Translation RNN in PyTorch (Lab)
-
- #6.1: Retrieval Augmented Generation - RAG (Part 1)
- #6.2: Retrieval Augmented Generation - RAG (Part 2)
- #6.3: Multi-Modal LLMs for Image, Sound and Video
- #6.3a: OpenAI CLIP for Zero-Shot Image Classification and Similarity (Lab)
- #6.4: LLM Agents with ReAct (Reason + Act)
- #6.5: Build LLM Agents from Scratch: PAL, ReAct & Langchain in 1 Hour
- #6.6: Hallucination Detection and Reduction for RAG systems (RAGAS, Lynx)
- #6.7: Faithfulness Checks for RAG pipelines (gpt4o-mini, Llama-index, RAGAS, Azure)
- #6.8: Understanding Reasoning LLMs (o1/o3, DeepSeek-R1, Gemini Thinking, Grok 3, Claude 3.7)
- #6.9: Design Patterns for Securing LLM Agents Against Prompt Injection
Part 1: Introduction
#1: Introduction and Roadmap
Welcome to the "LLM Chronicles". In this introductory video, I'll lay out the roadmap for navigating the world of Large Language Models. Throughout this series, I'll focus on the big ideas and aim to provide an intuitive grasp of key concepts, from the basics of neural networks to how Recurrent Neural Networks and Transformers function. My goal is to help you understand how things work without the fluff.
Join me as I set the course for a clear and intuitive exploration of LLMs.
Part 2: Neural Networks Basics
#2.1: Neural Networks and Multi-Layer Perceptrons
In this episode of the LLM Chronicles, we'll cover the basics of artificial neurons, see how they form multi-layer perceptrons, and learn how to model inputs and outputs for effective network processing. We'll also touch on vectorialization and its role in optimizing neural network implementations on GPUs.
#2.2: Multi-Layer Perceptrons and MNIST Digit Classification using PyTorch (Lab)
Welcome to the first hands-on lab session of the LLM Chronicles. Here we first implement Multi-Layer Perceptrons (MLPs) from scratch using matrix operations with NumPy. Following that, we set up an MLP using PyTorch for digit classification on the MNIST dataset.
Part 3: Training Neural Networks

#3.1: Loss Function and Gradient Descent
In this episode of the LLM Chronicles, we'll cover how to prepare datasets for effective training of neural networks. We'll then look at how the problem of training a network can be defined in terms of minimizing the loss function and we'll close by looking at how we can achieve this using gradient descent.
#3.2: Gradient Descent in PyTorch with Autograd (Lab)
In this hands-on lab we look at how PyTorch uses the Autograd library to implement the concepts of derivatives and gradient descent that we saw in the previous episode.

#3.3: Training with Gradient Descent and Optimizations(mini-batch, momentum, RMSProp, ADAM)
This is an exciting episode of the LLM Chronicles as we finally cover how neural networks are trained in practice and what a training loop looks like. We also cover a training method called mini-batch updates, comparing it with full-batch and incremental updates. We end this episode by looking at common optimizations of gradient descent, such as momentum, RMSProp and ADAM.
#3.4: Training the MNIST Perceptron with PyTorch (Lab)
In this lab we'll finally put everything together and using PyTorch we'll train our model to recognize the MNIST hand-written digits, using gradient descent and mini-batch updates.

#3.5: Evaluation, Overfitting and Underfitting + Bonus Lab
In this episode we look at common metrics to evaluate our models, such as accuracy, precision and recall. We also look at overfitting and underfitting, two common issues that can arise when training models, and what we can do to mitigate them.
Part 4: Language Models with Recurrent Neural Networks
#4.1: Recurrent Neural Networks
In this episode we'll look at how to model sequences of data, such as natural language, using Recurrent Neural Networks. We'll peak into the implementation of an RNN layer, looking at all the operations involved in the forward pass. Finally, we'll look at how good they are at remembering information from the past and at common issues that arise during training (vanishing and exploding gradients). We'll finish by looking at how Long short-term memory cells can help mitigate some of these issues.
#4.2: RNN and LSTM Cells in PyTorch (Lab)
In this short lab we'll first implement an RNN layer by hand to understand all the computations in the forward pass. after that, we'll look at PyTorch's implementation of RNNs and LSTM cells.

#4.3: Language Modeling with RNNs
In this episode we'll look at how to model sequences of data, such as natural language, using Recurrent Neural Networks. We'll peak into the implementation of an RNN layer, looking at all the operations involved in the forward pass. Finally, we'll look at how good they are at remembering information from the past and at common issues that arise during training (vanishing and exploding gradients). We'll finish by looking at how Long short-term memory cells can help mitigate some of these issues.
#4.4: Building a Word-Level Language Model in PyTorch(Lab)
In this lab we build a word-level language model using an RNN in PyTorch.
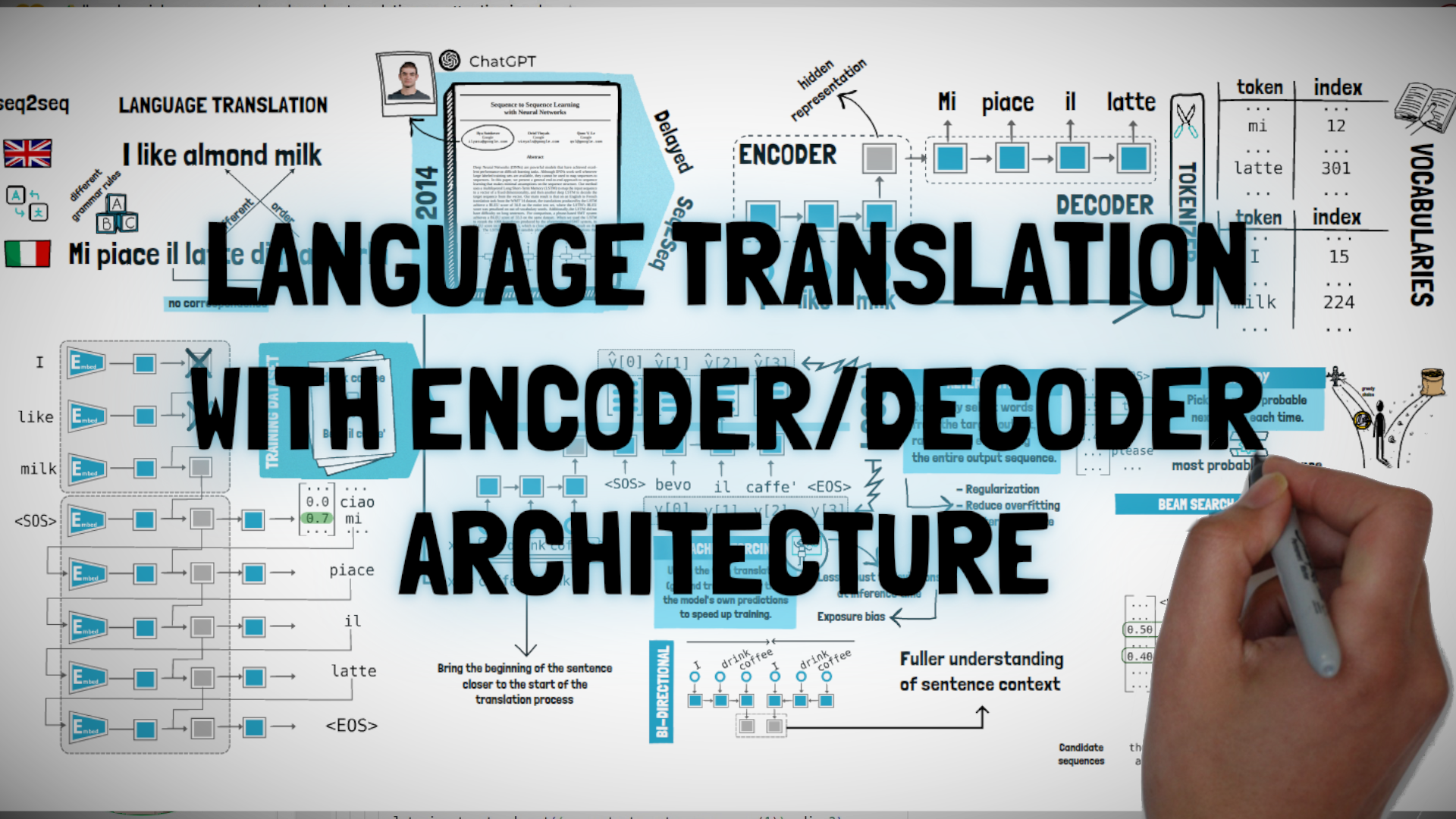
#4.5: Encoder/Decoder RNN for Language Translation (Seq2Seq)
In this episode we explore the seminal work on Language Translation with Recurrent Neural Networks(RNNs) that sparked key innovations that power advanced language models like OpenAI's ChatGPT and Google's Gemini. Specifically, we'll look at how the encoder/decoder architecture can be used to solve the problem of alignment for seq2seq tasks such as language translation, as described by Ilya Sutskever at al. in a 2014 paper titled “Sequence to Sequence Learning with Neural Networks”.
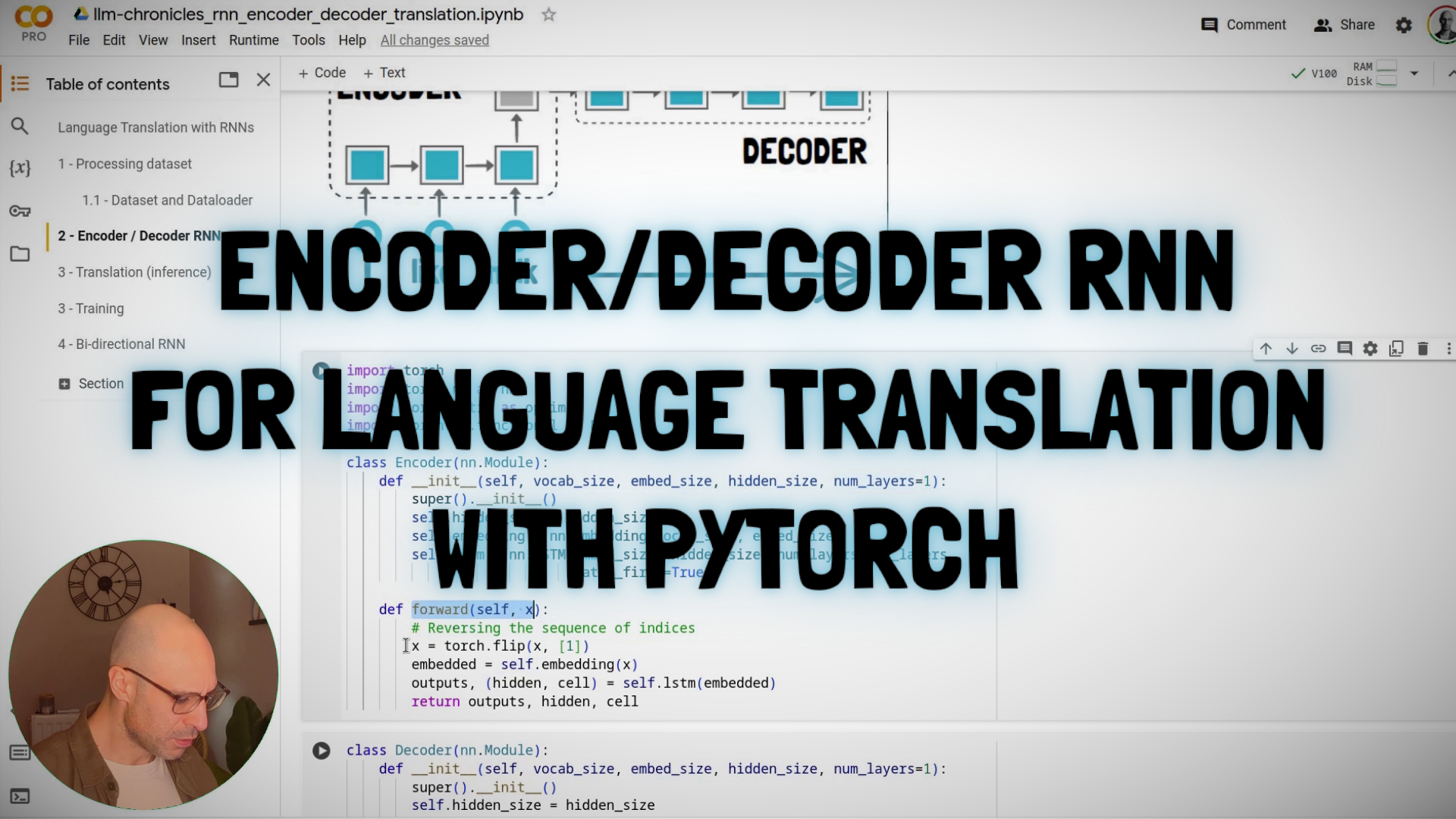
#4.6: Building an Encoder/Decoder RNN in PyTorch (Lab)
In this lab we'll use PyTorch to build a encoder/decoder RNN for language translation, similar to the model described in the 2014 paper "Sequence to Sequence Learning with Neural Networks” by OpenAI's chief scientist Ilya Sutskever. Our RNN layers will use LSTM (Long Short-Term Memory) cells.
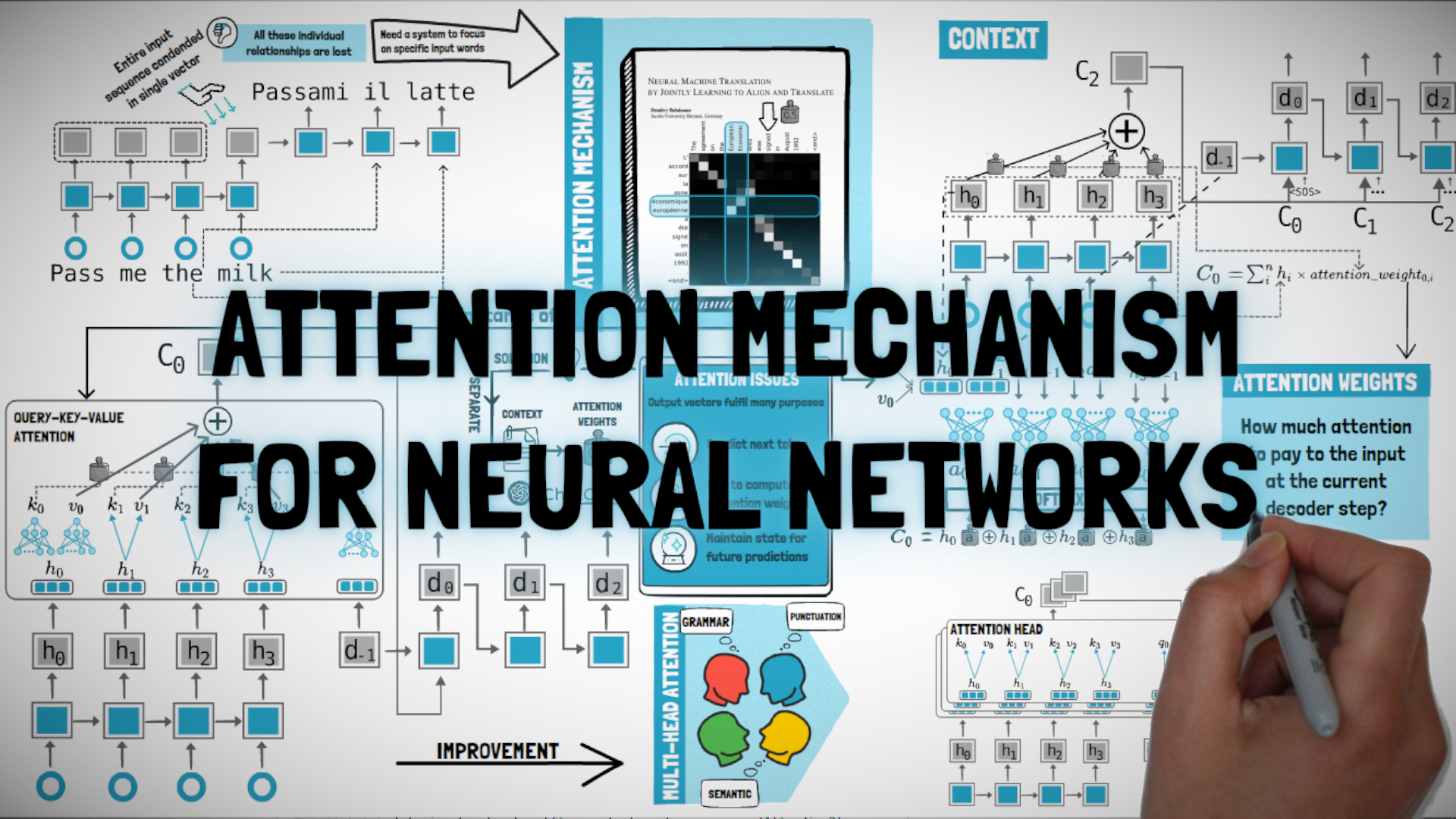
#4.7: Attention Mechanism for Seq2Seq RNNs
In this episode we'll cover the so-called "attention mechanism" for seq2seq tasks with Neural Networks. This was first introduced by Bahdanau at al. in 2014 to improve the performance of encoder/decoder RNNs used for language translation and proved fundamental to create the Transformer architecture that powers modern LLMs.
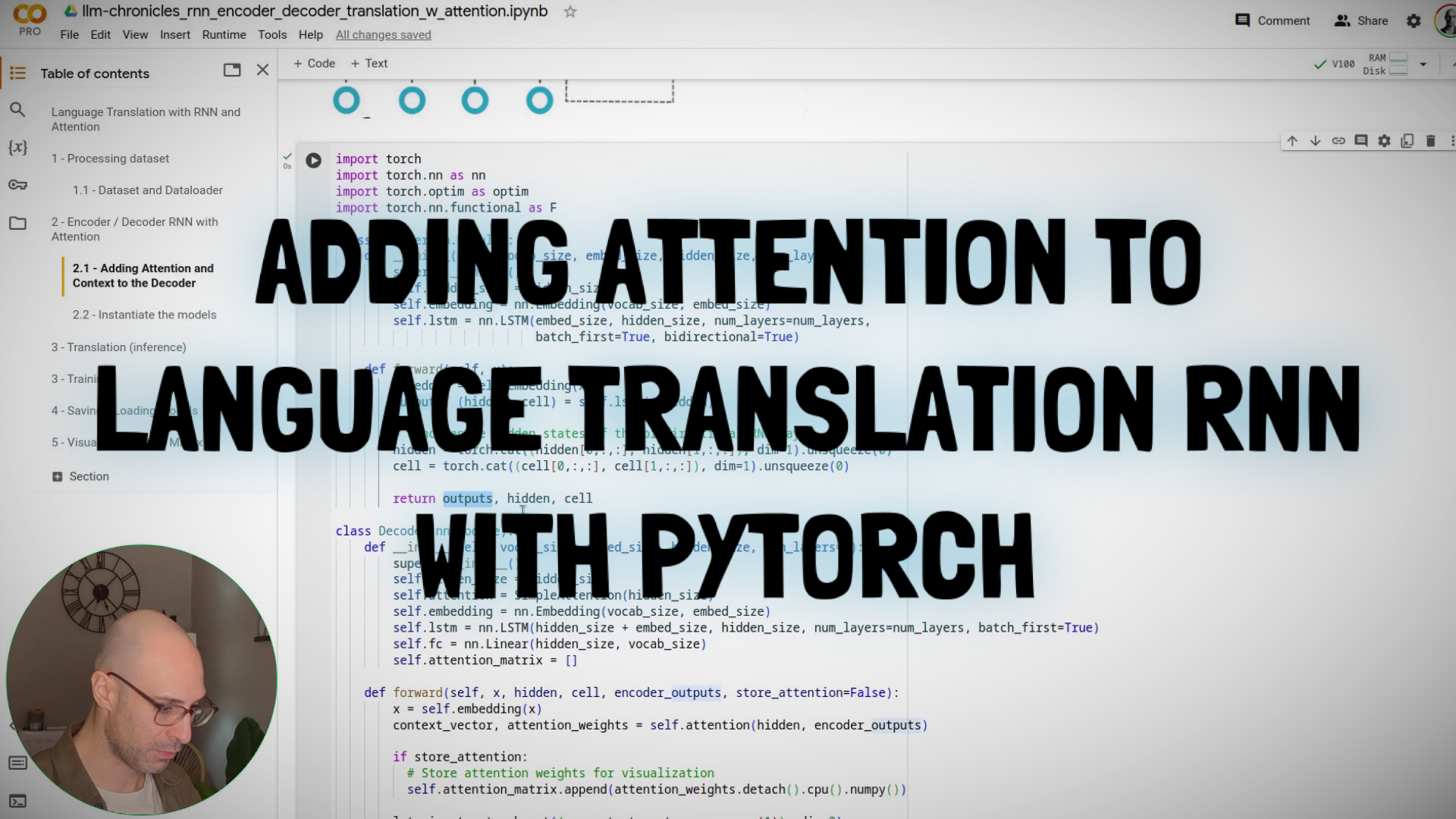
#4.8: Adding Attention to the Language Translation RNN in PyTorch (Lab)
In this lab we'll add a simple attention mechanism to our language translation RNN. This will be similar to the method described in Bahdanau et al.'s seminal paper from 2015 titled "Neural Machine Translation by Jointly Learning to Align and Translate".
Part 5: Large Language Models and Real-World Applications
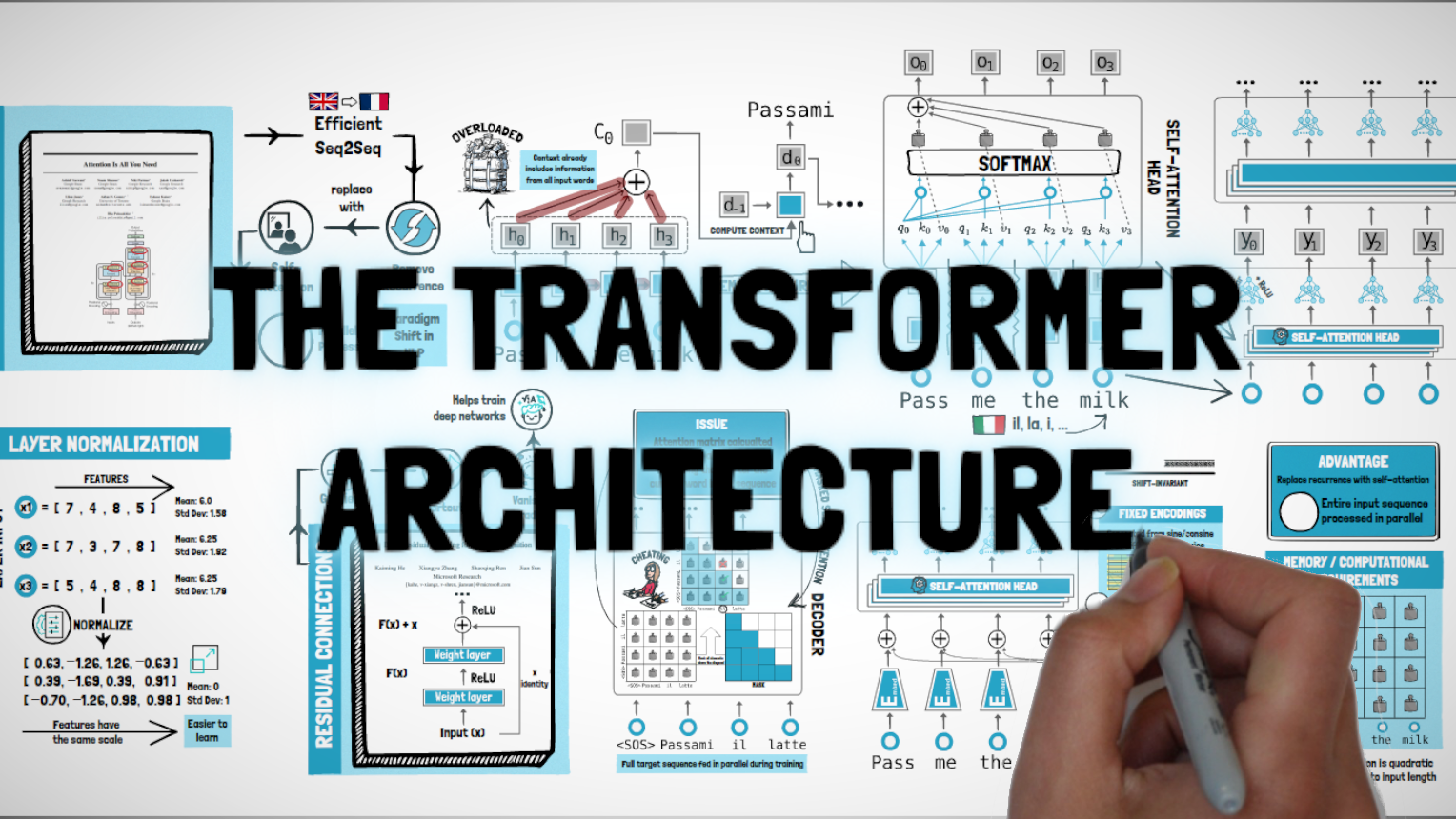
#5.1: Transformers and Self-Attention
This episode covers the groundbreaking Transformer architecture introduced by Google researchers in 2017. We cover the introduction of self-attention and positional encoding to remove recurrence and increase parallelization, which led to greater performance and scalability.

#5.2: Making LLMs from Transformers (BERT, Encoder-based)
This episode dives into how to build LLMs from the encoder component of Transformers. Specifically, we look at the similarities and differences between the encoder and decoder parts of a Transformer, we then see how Google used the encoder to build BERT via pre-training and fine-tuning.
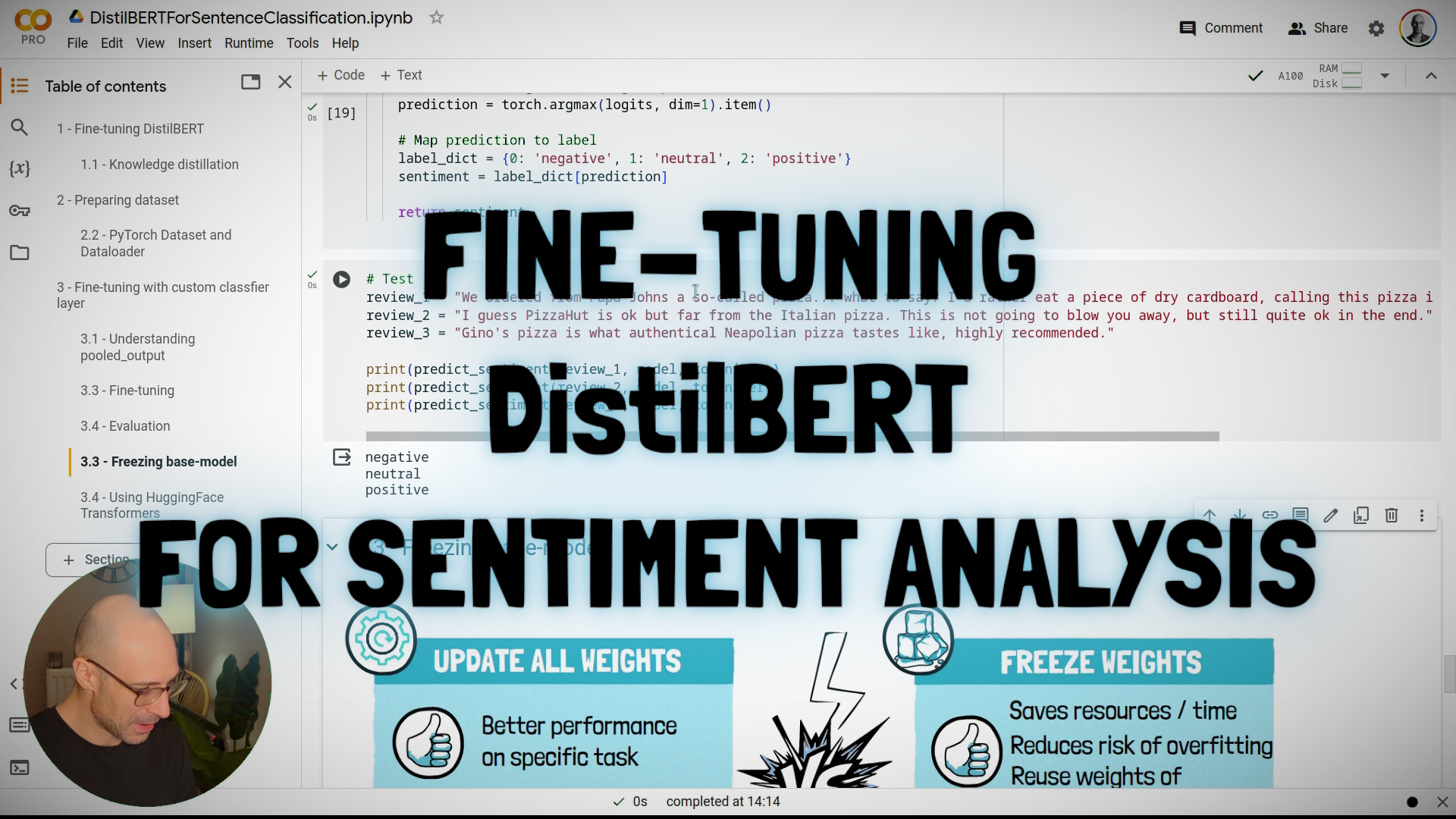
#5.3: Fine-tuning DistilBERT for Sentiment Analysis (Lab)
In this lab we'll see how to fine-tune DistilBERT for analyzing the sentiment of restaurant reviews. We'll look at how to do this from scratch, adding the specific layers for classification by hand. We'll conclude by looking at how to use the HuggingFace Transformers library for this.

#5.4: GPT, Instruction Fine-Tuning, RLHF
In this episode well see how OpenAPI built the models behind ChatGPT from the decoder part of a Transformer. We'll see how Generative Pre-Trained Transformers are fined tuned for instruction following in natural language and how hey are aligned using RLHF (Reinforcement Learning from Human Feedback).
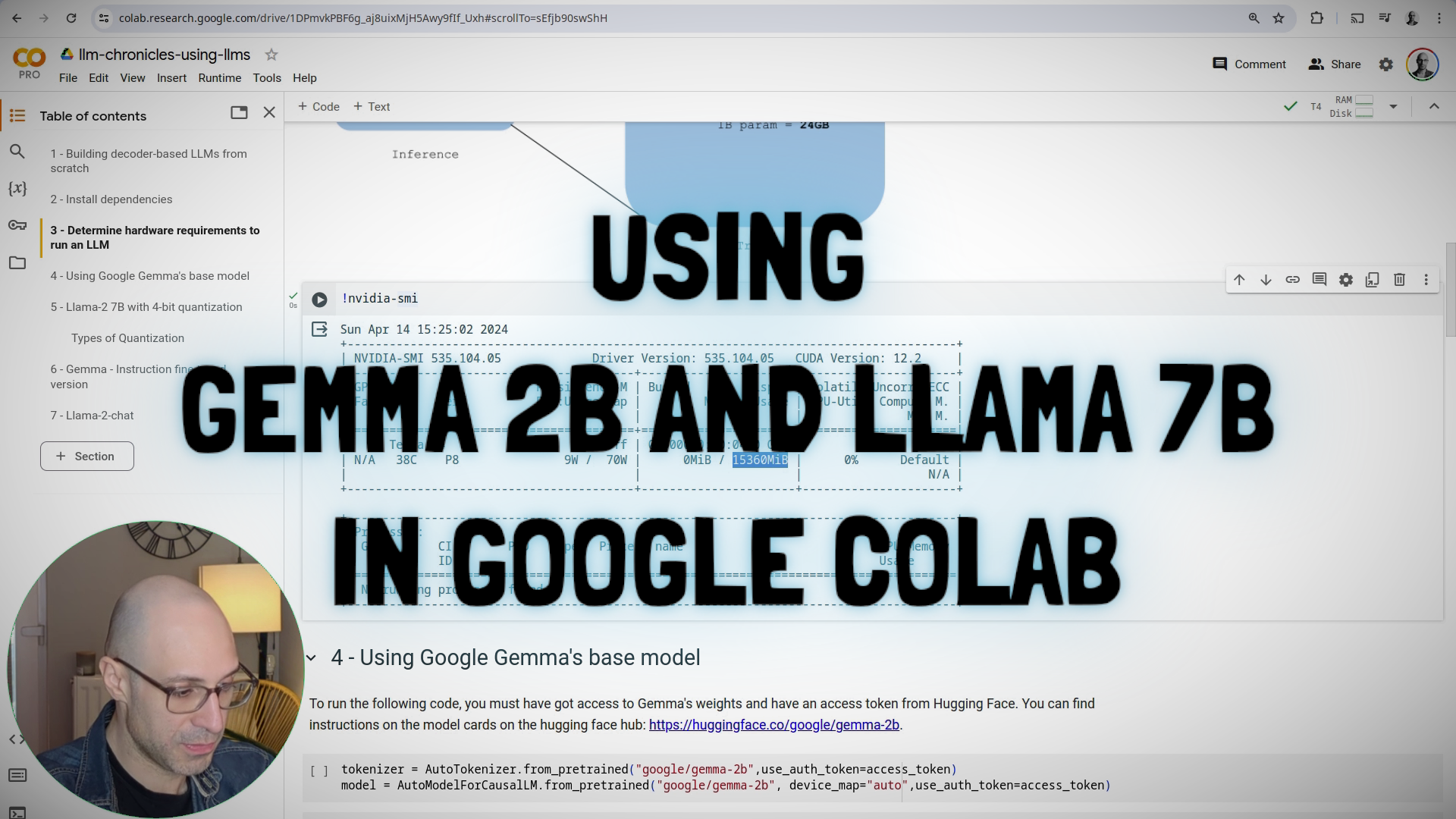
#5.5: Running Gemma 2B and Llama-2 7B with Quantization
In this lab we'll get hands-on with two open-weight LLMs, Gemma 2B and Llama-2 7B. We'll see how to run them inside Google Colab notebooks within the free T4 tier. We'll take a look at the base and the instruction tuned versions, to understand the difference and the impact of fine-tuning and RLHF on the performance of the models.

#5.6: LLM Limitations and Challenges
In this episode we'll cover the main limitations and challenges with current Large Language Models (LLM). This helps cut through the hype and get a clear picture of what the technology is good for and what needs improvement.
Part 6: LLM Applications and Advancements

#6.1: Retrieval Augmented Generation - RAG (Part 1)
This episode introduces RAG (Retrieval Augmented Generation) with LLMs. We cover all the basic concepts, including semantic search with vector databases. We finish with a quick lab showing how to create a basic RAG system for the Huberman Lab Podcast with Langchain, GPT-3.5, BGE embeddings and ChromaDB.

#6.2: Retrieval Augmented Generation - RAG (Part 2)
This episode explores some issues with RAG, covering solutions and common strategies to mitigate them and improve performance such as self-query, parent document retrieval and HyDE (Hypothetical Document Embedding).

#6.3: Multi-Modal LLMs for Image, Sound and Video
In this episode we look at the architecture of a multi-modal LLM, discussing the general training process of an MLLM. After that, we'll focus on vision and explore Vision Transformers and how they are trained with contrastive learning. Vision Transformers are the most commonly used building block in MLLMs with vision capabilities. Finally, we'll get hands-on and look into Google's open-weight PaliGemma, analysing its implementation to see these concepts in action within a real-world multi-modal LLM.
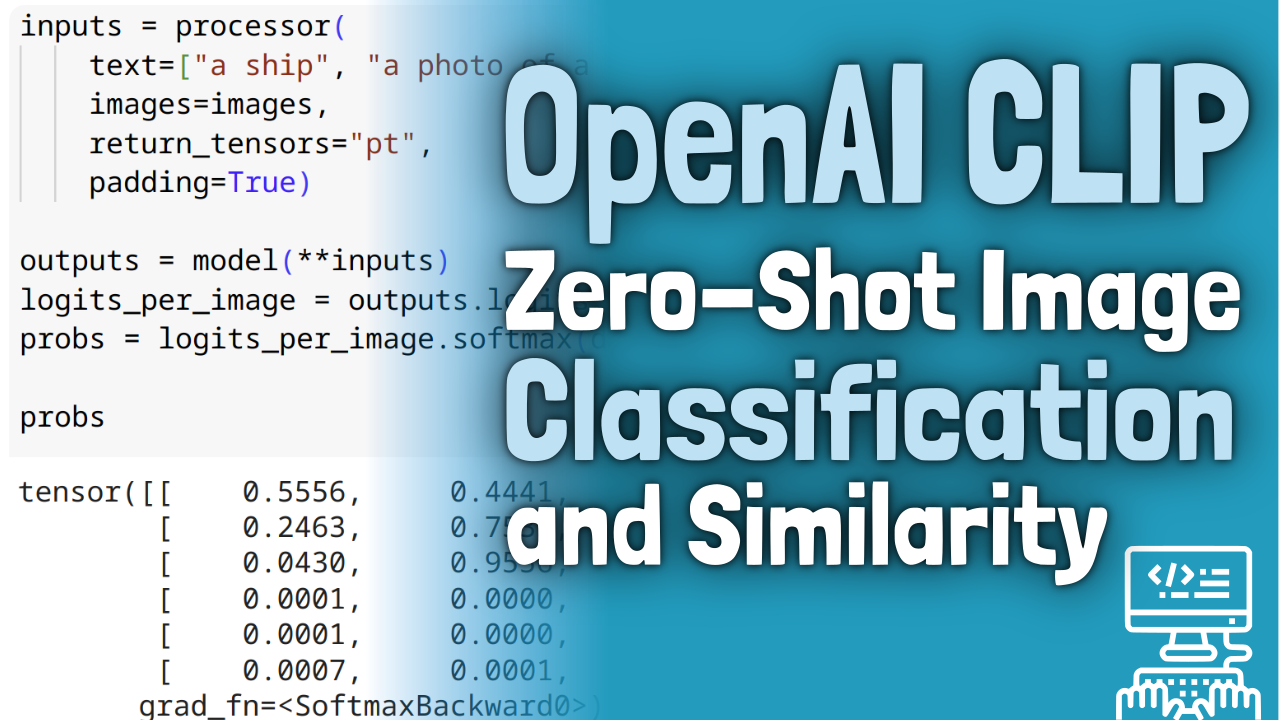
#6.3a: OpenAI CLIP for Zero-Shot Image Classification and Similarity
In this lab we look at how to use the OpenAI CLIP model for zero-shot image classification and image similarity. We will explore loading CLIP from HuggingFace and also deploying it on Azure AI Studio.

#6.4: LLM Agents with ReAct (Reason + Act)
In this episode we'll cover LLM agents, focusing on the core research (that helped to improve LLMs' reasoning while allowing them to interaction with the external world via the use of tools. This includes Chain of Thought prompting, PAL (Program-aieded Language Models) and ReAct (Reason + Act) as used in Langchain and CrewAI agents.

#6.5: Build LLM Agents from Scratch: PAL, ReAct & Langchain in 1 Hour
In this video, I'll guide you through building LLM agents from scratch, starting with paradigms like PAL (Program-Aided Language models) and ReAct (Reason + Act) to enhance reasoning and agent behavior. First, you'll learn how to implement these manually. Then, I'll show you how to achieve the same using the Langchain framework, including LangChain Expression Language (LCEL). After that, I'll walk you through how to switch between different language models like GPT-4, Llama 3.1, and Mixtral on platforms like TogetherAI and Groq, giving you flexibility in agent design. Finally, I'll demonstrate how to use OpenAI's function calling as an alternative to a direct ReAct prompt, adding another layer of functionality to your agents.

#6.6: Hallucination Detection and Reduction for RAG systems (RAGAS, Lynx)
This episode covers LLM hallucinations — why they happen, how to detect them, and ways to reduce them in RAG pipelines. We'll discuss key tools like RAGAS metrics for measuring faithfulness, context relevance, and answer relevance, along with techniques like using LLMs as judges and embedding models to catch hallucinations. Plus, we'll discuss the Lynx model, a fine-tuned version of Llama-3 built to identify and limit hallucinations, making responses more accurate.

#6.7: Faithfulness Checks for RAG pipelines (gpt4o-mini, Llama-index, RAGAS, Azure)
In this lab we look at how to detecting the faithfulness or groundedness of LLM responses in a RAG pipeline to ensure they are rooted in the context provided. We see how to do this using an LLM-as-judge (gpt4o-mini, Lynx), and how frameworks like Llama-index and Ragas deal with this. We also look at the Groundedness API in Azure AI Content Safety and finish by comparing the different solutions on MiniHaluBench, a small dataset created from HaluBench.

#6.8: Understanding Reasoning LLMs (o1/o3, DeepSeek-R1, Gemini Thinking, Grok 3, Claude 3.7)
Reasoning LLMs have become one of the biggest topics in GenAI. OpenAI's o1 model launched in late 2024, sparking claims of a fundamental shift in AI reasoning. But soon after, Google's Gemini Thinking, DeepSeek's R1, xAI's Grok 3, and now Anthropic's Claude 3.7 followed.
So, was o1 truly a breakthrough, or just another step forward? In this video, I break down reasoning models—what they are, how they're trained, and crucially, how they are not fundamentally different from general-purpose LLMs.

#6.9: Design Patterns for Securing LLM Agents Against Prompt Injection
This episode covers the six core security design patterns presented in the paper “Design Patterns for Securing LLM Agents against Prompt Injections” by Beurer-Kellner et al. I walk through the main ideas behind each pattern, highlight their strengths and trade-offs, and demonstrate working code examples for each approach.
I find this paper to be a very clear and practical resource for understanding structural defences against prompt injection, and all examples shown here are available in the linked GitHub repository.